| Pan Zhang | Bo Zhang | Dong Chen | Lu Yuan | Fang Wen |
| University of Science and Technology of China | Microsoft Research Asia |
 |
| We propose an exemplar-based image synthesis. Given the exemplar images (1st row), our network translates the inputs in the form of segmentation mask, edge and pose, to photorealistic images (2nd row) under the guidance of dense correspondence to the exemplar image. |
Abstract
We present a general framework for exemplar-based image translation, which synthesizes a photo-realistic image
from the input in a distinct domain (e.g., semantic segmentation mask, or edge map, or pose keypoints), given an
exemplar image. The output has the style (e.g., color, texture)
in consistency with the semantically corresponding objects in the exemplar. We propose to jointly learn the
cross domain correspondence and the image translation, where both tasks facilitate each other and thus can be
learned with weak supervision. The images from distinct domains are first aligned to an intermediate domain where
dense correspondence is established. Then, the network synthesizes images based on the appearance of semantically
corresponding patches in the exemplar. We demonstrate the
effectiveness of our approach in several image translation tasks. Our method is superior to state-of-the-art
methods in terms of image quality significantly, with the image style faithful to the exemplar with semantic
consistency. Moreover, we show the utility of our method for several applications.
Network architecture
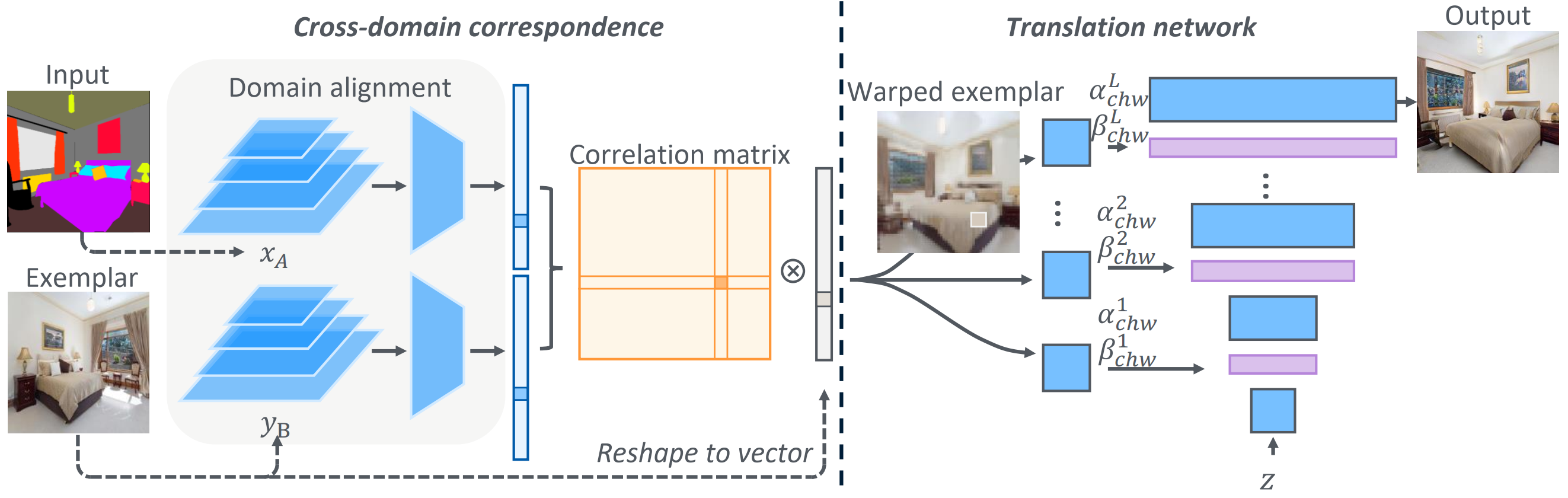 |
CoCosNet |
Demo
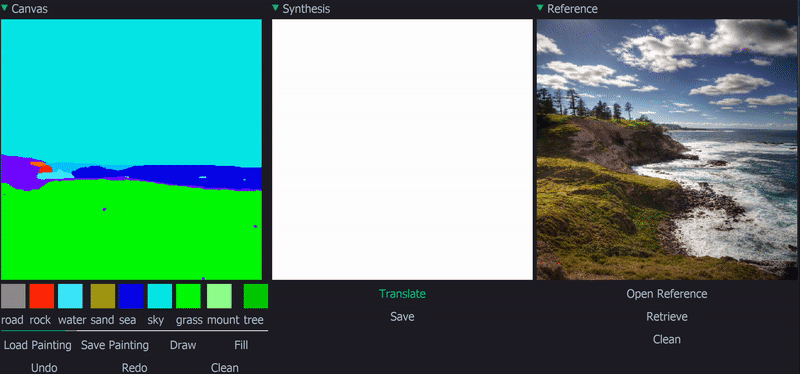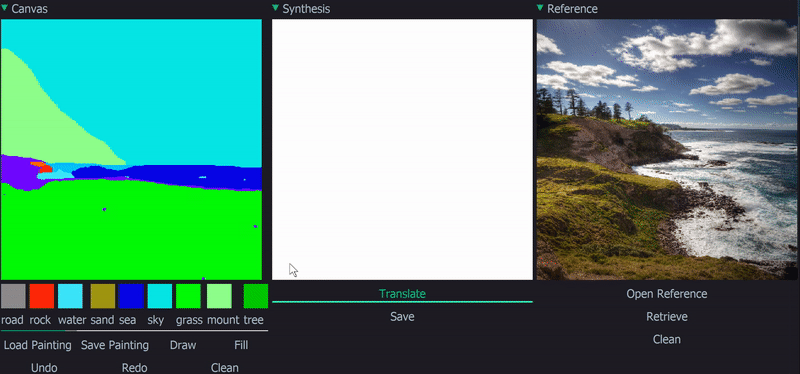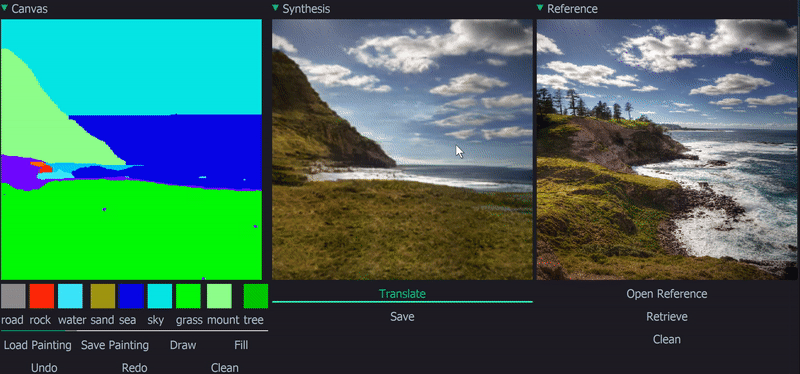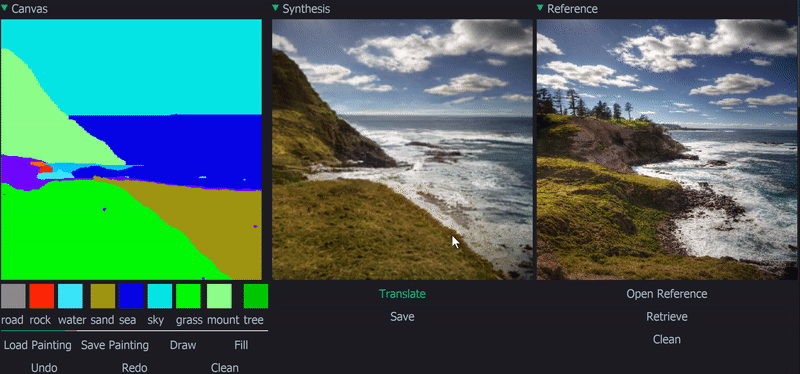 |
Makeup Transfer
 |
| Given a portrait and makeup strokes (1st column), we can transfer these makeup edits to other portraits by matching the semantic correspondence. We show more examples in the supplementary material. |
Image Editing
 |
| Given the input image and its mask, we can semantically edit the image content through the manipulation on the mask. |
Paper
 |
"Cross-domain Correspondence Learning for Exemplar-based Image Translation", [PDF] [Code] [Supplementary Doc.][Slides] [BibTeX] |
Last updated: April 2020